

Estamos en semanas con muchas novedades para la industria de los datos en el fútbol. Especialmente por los anuncios de diferentes empresas proveedoras de datos, cuyos desarrollos permiten la consolidación de indicadores y la generación de análisis se ajustan cada vez a los pedidos futboleros por parte de entrenadores y medios.
Para entender donde estamos parados, va un poco de contexto histórico: Un breve timeline histórico que a grandes rasgos y de manera muy resumida, presenta las distintas etapas del uso de datos en el fútbol, haciendo la salvedad que los tramos redondeados funcionan más como referencia que como un decálogo de fechas exactas:
1950 – 1990s | Una gran fase donde entrenadores y analistas pioneros que sientan las bases y demuestran que el fútbol puede generar información al igual que otros deportes. Hay muchas historias de origen disponibles, pero podemos decir que esto lo arranquó Charles Reep en Inglaterra, lo formalizó Lobanovsky en la URSS y lo llevó al mainstream Arsene Wenger, primero en el Mónaco y luego en el Arsenal inglés.
1990s – 2010s | Una fase de expansión empujada fundamentalmente por la aparición y sistematización del trabajo de las empresas proveedoras de datos. Opta es la compañía que encabeza este segmento, desarrolla la metodología para la obtención de información cuantitativa en los partidos de fútbol, y pone a disposición de los cuerpos técnicos, pero también de la prensa, una serie de estadísticas que antes debían tomarse “a mano” o que directamente eran imposibles de capturar.

2010s – 2020 | Una fase de complejización de los análisis, donde sobre el número de eventos relevados por partido se empezaron a construir métricas más segmentadas (posesión por tramos, vínculos entre jugadores, etc) y otras más elaboradas como los goles esperados (xG), las redes de pases y la ponderación de las asistencias.
Al mismo tiempo entrenadores y prensa, salvo casos excepciones, consolidan en su trabajo cotidiano el uso de datos. Dejan de ver a los analistas como una contraparte o amenaza y comienza un proceso de feedback entre ambas partes que desemboca en el momento actual.
2020s | Empresas proveedoras y analistas trabajan sobre la mejora de ideas que se desarrollaron previamente. Se agrega cada vez más contexto a cada uno de los eventos relevados y se mejoran los modelos detrás de las métricas creadas en años anteriores.
Contextualizar el dato
“La computadora no hace goles” es el lugar común de quienes insisten con el fútbol de hace 30 años, ya hemos hablado largo y tendido de porqué esa crítica no tiene ningún sentido e incluso ha quedado en desuso, aún por entrenadores de la vieja escuela.
La segunda crítica clásica al uso de datos tiene mucha más lógica y alude a la descontextualización del dato tal y como es presentado habitualmente. Por ejemplo, habitualmente se menciona la cantidad total de pases que da un equipo durante un partido o el porcentaje de posesión, sin aclarar el tipo de pase o la zonas de tenencia.
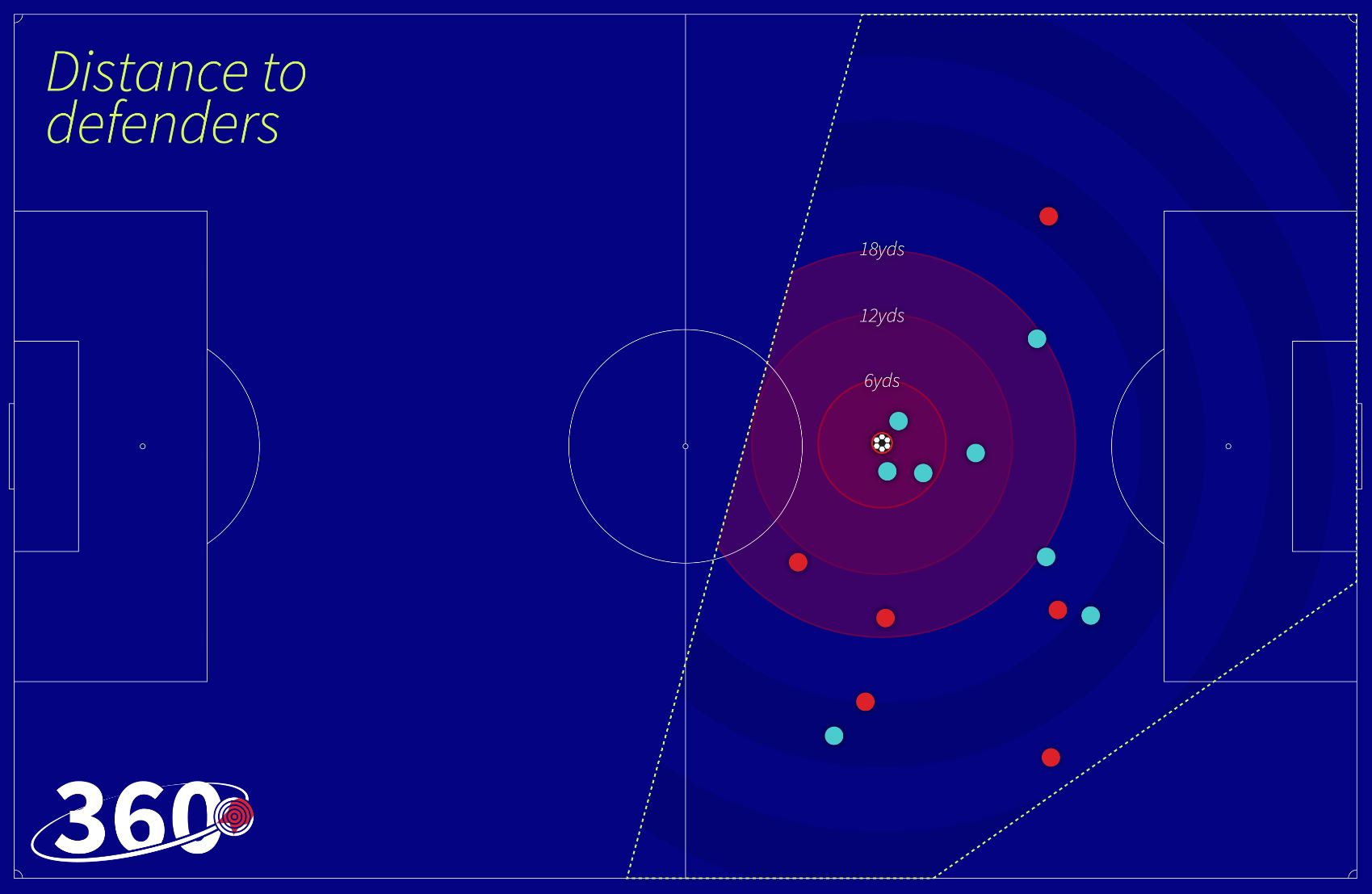
Los analistas han trabajado en mejorar la contextualización de cada evento, hoy por hoy se puede tipificar al detalle cada tipo de pase (por dirección, parte del cuerpo que la ejecuta, velocidad, etc), pero el agregado más interesante que se sumo en el último tiempo es la posibilidad de entender toda la situación que rodea a la ejecución del mismo.
Las primeras empresas en contextualizar estos eventos, fuero aquellas que capturan datos mediante video (SportsVU, Métrica Sports, SkillCorner, Signality, etc) permitiendo mostrar en cada jugada la posición de los restantes futbolistas y no solamente del jugador que realiza la acción y del recorrido del balón. Esto permite, entre otras cosas, entender si el pase fue bajo presión o no, si “rompió líneas” o si puso a un compañero en situación favorable para convertir.
La semana pasada, Ted Knutson CEO de la empresa proveedora de datos Statsbomb, anunció la salida al mercado de su nuevo producto Statsbomb 360 que captura todos estos datos contextuales mejorando la capacidad de interpretar cada uno de los eventos que se generan en un partido de fútbol.


De esta manera, los analistas tendrán más opciones a la hora de explicar que dicen los datos y podrán argumentar fácilmente a quienes supongan que simplemente se computan cantidades de pases y no toda esta gama de datos complementarios que, como dijimos, ya incluía variables de tipificación y ahora suma características respecto al entorno. Y esto se aplica tanto a cada pase realizado como en cada uno de los pases recibidos.
En consecuencia, las posibilidades de análisis crecen exponencialmente, pudiendo medir conceptos favoritos de los entrenadores como la toma de decisión respecto a los pases, la resolución bajo presión propia, o la manera que se esta marcando la recepción de pelota rival.

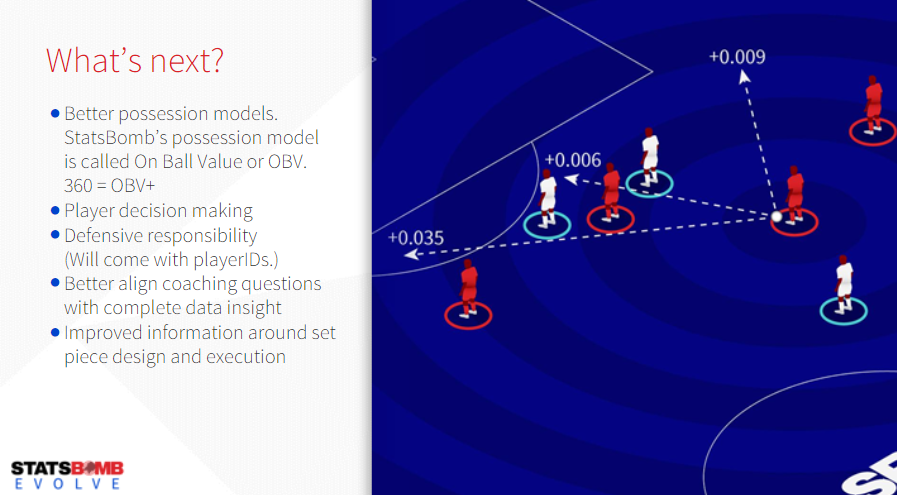
Adicionalmente, Knutson anunció que la empresa está desarrollando un modelo propio de análisis de la tenencia o contribución de los jugadores en la posesión, lo llamaron On Ball Value (OBV) y pareciera tener características similares a métricas como xT o VAEP cuya consolidación supondrá para la industria una revolución similar a la de los goles esperados.
El anuncio comercial saliente de esta presentación, es que uno de los primeros clubes en confiar en este desarrollo, es nada más y nada menos que el Liverpool inglés, cuyo equipo de análisis de datos ha hecho aportes particularmente destacables en los últimos años.
Mejoras en los modelos
Algunos años atrás, la introducción de los goles esperados (xG) significaba un diferencial entre empresas proveedoras. Una vez establecida la métrica que como sabemos es permite diferentes maneras de calcular, la carrera fue por ver que empresa o analista había desarrollado el mejor modelo en la práctica.
Este fue otro de los focos de la presentación de Statsbomb Evolve de la semana pasada, Knutson hizo particular hincapié en las bondades del modelo de su empresa respecto a otras compañías, pero también a las mejoras introducidas en su propio desarrollo a partir de la ampliación del contexto de captura de los datos de su empresa.
Aquí la lógica es parecida a la que mencionábamos de los pases. Originalmente los modelos contemplaban básicamente la zona del remate, el ángulo de tiro y el tipo de jugada. Posteriormente se agregaron el tipo de pase previo y la posición de compañeros y rivales, esto permitió ajustar el valor de los xG en caso de que la definición sea sin el arquero, o bien sea un remate muy cerca de la portería rival pero plagado de defensores presionando al atacante.
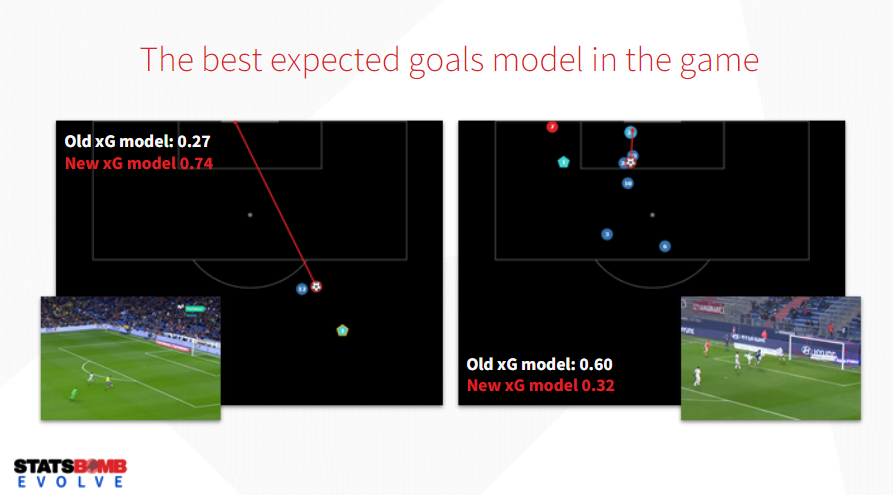
En este nuevo escenario, Statsbomb agrega una nueva variable: la altura del impacto de la pelota por parte del rematador. Una idea que, si lo pensamos, tiene muchísima lógica ya que técnicamente tiende a ser más difícil impactar un remate de volea que empujarla sobre el ras del suelo. Otra vez, la industria de análisis presta atención a críticas y señalamientos de futbolistas y entrenadores, y ajusta en función de estos.
Una industria que empareja para arriba
El anuncio de Statsbomb Evolve fue una de las grandes noticias de la industria de los datos en el fútbol, en la búsqueda por diferenciarse comercialmente de otras compañías, Knutson hizo foco en que mientras otras empresas crean datos para los medios y algunas lo hacen sobre el taggeo de videos, Statsbomb es una iniciativa de analistas y para analistas.
Ciertamente, Statsbomb que es la empresa más nueva en unirse a la industria, ha desafiado continuamente los estándares de la misma buscando diferenciarse en la cantidad y calidad de los eventos relevados por partido. De cualquier manera, esto no implica que sus competidores estén de brazos cruzados ni mucho menos.
Stats Perform tendrá su Pro Forum este 24 de marzo, el evento que suele ser el puntapie de gran parte de las innovaciones de la industria de los datos en el fútbol. Los speakers y trabajos anunciados también dan cuenta de la fase actual que mencionábamos al comienzo: foco en mejorar la calidad de los modelos y una mayor contextualización de los datos.
Los trabajos anunciados se permiten atender fases específicas del juego como evaluación de la presión sobre el rival y la contribución defensiva de los jugadores (históricamente relegada por los datos). Hay también anunciado un trabajo sobre los retornos del scouting basado en datos, otro de los ejes de la industria por estos días, no solo para empresas generadoras del dato sino también para la gran gama de startups (y algunas empresas ya consolidadas en el mercado) que han hecho del datascouting el core de su negocio.

Otro de los anuncios de Stats Perform en los últimos días, fue la creación de un newsletter y una web especializada en análisis, que lleva el nombre de “The Analyst” y que contará con artículos y trabajos de su equipo de inteligencia artificial y el aporte de los editores y analistas de datos que la compañía tiene alrededor del mundo.
Wyscout anunció mejoras en sus métodos de scouting hace algunos meses, integrando datos y video de manera más simple para sus usuarios. Por el lado de InStats, la empresa anunció un acuerdo de colaboración con SciSports, la empresa de origen holandés creadora del VAEP (una de las métricas sobre posesión más interesantes que se hayan desarrollado en los últimos años) y desarrolladora de una de las plataformas de scouting más interesantes del mercado.







Follow Me